
Learn about Flatiron’s latest discoveries and key learnings in applying machine learning (ML) and large language models (LLM) to unlock insights on large patient populations.
Technology is fundamental to Flatiron’s mission of learning from the experience of every person with cancer. In particular, machine learning is critical to understanding the experience of people with cancer at scale.
As cancer care becomes increasingly targeted, expanding the number of patients that we can learn from allows us to deliver rigorous insights about ever narrower populations with specific characteristics and experiences. These populations — whether defined by rare biomarkers, distinctive histologies, or atypical patterns of treatment — are increasingly the locus of breakthroughs in cancer care. While clinical expertise forms the core of our real world data curation efforts, technology allows that expertise to scale.
Figure 1: ChatGPT knows its limitations in commenting on its ability to extract medical information from Electronic Health Record (EHR) datasets

Why large language models?
Like many, we have been galvanized by the rapid pace of advancement in large language models LLMs over the past year. While they may seem to have come out of nowhere, LLMs like ChatGPT build on years of scientific and technological development in natural language processing (NLP), including many technologies currently used at Flatiron. Yet they also represent a transformative advance. Whereas previous NLP systems would need to be trained on specific tasks using painstakingly hand-labeled data, ChatGPT and other LLMs are generalists. In some cases, they can simply be instructed with a task description, forgoing training altogether.
So are LLMs going to completely change the way that we curate real world data at Flatiron? Probably not. In exploring their capabilities, we have learned some key lessons about what they can and cannot do.
LLMs: Basic interpretation errors and hallucinations
There’s no doubt that it can be thrilling to ask an LLM for a summary of a patient’s cancer diagnosis and quickly receive a well-formatted table, complete with dates and relevant details like stage and histology. Yet all too often, a closer look will reveal errors that are both subtle and dramatic. Figure 2 shows what that can look like.
Figure 2: A formatted table of patient data produced by an LLM

While LLMs excel at style, they can still lag behind in substance. A purported diagnosis date might actually be drawn from a surgical procedure, or even a date of birth. A benign polyp might be mistaken for a tumor. Entirely novel forms of cancer might be hallucinated by stringing together disconnected fragments from the doctor’s notes.
When thinking about why LLMs make such basic mistakes, it can be useful to consider how they are built. During training, LLMs have been exposed to an enormous amount of text scraped from the internet. They’ve seen news articles, blog posts, fan fiction, computer code, recipes, poems, message boards, scientific papers, and much else. They’ve ingested all of Wikipedia, and that represents just 1/1000th of their training data.
But one kind of content that LLMs haven’t seen much of are clinical records. For good reason: your doctor’s notes can’t simply be scraped from the internet. And they don’t look like any of the other content that LLMs are trained on. Doctors tend to write in terse, highly technical shorthand. So calling a doctor’s note “natural language” is a bit of a stretch.
LLMs: Lack of specialized knowledge
The questions that we ask when curating real world datasets are highly specific. It’s not enough to know that a patient has been diagnosed with, say, lung cancer; we also need to parse out the subtle distinctions between different lung cancer histologies. Identifying a milestone in a patient's journey can be highly nuanced, such as distinguishing a tumor’s spread to local lymph nodes from its metastasis to a distant site. Flatiron’s research oncologists have crafted detailed guidelines that our clinical abstractors follow when curating data.
Figure 3: Flatiron clinical abstractors follow detailed guidelines to curate data
Guidelines for specific abstraction forms can run to dozens, sometimes even hundreds of rules, and each rule must be followed carefully to ensure the validity of the resulting datasets. While LLMs can also follow rules to perform a task, there’s a limit to how much detail and nuance you can provide before they get hopelessly confused.
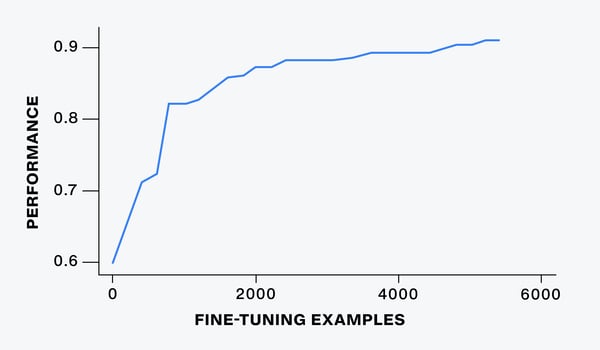
As a result, we are finding that the best way to take advantage of these powerful new models might not look all too different from how we use the previous generation. Hand-labeling examples and “fine-tuning” the LLMs can be more effective than crafting prompts with detailed instructions. Fine-tuning aims to build on these models’ generalist capabilities — their facility with language and background knowledge — while teaching them to perform a specific task exactly the way we want. But it’s also important to ask whether a fine-tuned LLM actually outperforms a smaller, purpose-built ML model. As with any powerful new technology, we should opt for the complexity and cost of an LLM only when we truly need it.
Figure 4: LLM performance based on number of fine-tuning examples
Data, technology and humans
More than anything, clinical expertise remains essential. Our experts curate the ground truth data that we use to train and validate all of our machine learning systems, including LLMs. But their role is now expanding to involve actively reviewing LLM outputs and consulting on where the models are missing some nuance or getting an answer wrong. We believe that having a human in the loop will remain critical for making the best use of these remarkable technological achievements as we continue to seek insights that can improve and extend lives.


